第 8 章 内存管理策略

背景
基本硬件
程序需要从磁盘中被移入内存,再分配一个进程来运行
CPU 可以直接访问的通用存储只有内存和处理器内置的寄存器
CPU 内置寄存器通常可以在一个 CPU 时钟周期内完成访问
完成内存的访问可能需要多个 CPU 时钟周期
在 CPU 寄存器和内存之间设置了高速缓存(cache)
为了系统操作的正确应保护内存

Memory Hierarchy

基地址寄存器和界限地址寄存器定义逻辑地址空间
基地址寄存器(base register)含有最小的合法的物理内存地址
界限地址寄存器(limit register)指定了范围的大小
地址绑定
符号地址(Symbolic Address):源程序中的各种变量的名字。
可重定位地址(Relocatable Address):地址在内存中相对某一位置的偏移量。编译器将符号地址转换为可重定位地址。
绝对地址(Absolute Address):一个数值,地址在整个内存中的偏移量。链接器将可重定位地址转换为绝对地址。
- 指令和数据绑定到存储器地址可以发生在三个不同的阶段:
- 编译时(compile time):如果在编译时就已知道进程将在内存中的驻留地址,就可以生成绝对代码(absolute code)。如果将来开始地址发生变化就必须重新编译。
- 加载时(load time):如果在编译时不知道进程将驻留在何处,则编译器就应生成可重定位代码(relocatable code)。如果开始地址发生变化,只需重新加载到用户代码以合并新的更改。
- 执行时(execution time):如果进程在执行时可以从一个内存段移到另一个内存段,则绑定应延迟到执行时才进行。采用这种方案需要特定硬件(例如基地址寄存器和界限地址寄存器)支持。

逻辑地址空间与物理地址空间
逻辑地址(logical address):CPU 生成的地址,也称为虚拟地址(virtual address)
物理地址(physical address):内存单元看到的地址(即加载到内存地址寄存器的地址)
编译时和加载时的地址绑定方法生成相同的逻辑地址和物理地址
执行时的地址绑定方案生成不同的逻辑地址和物理地址
逻辑地址空间:由程序所生成的所有逻辑地址的集合
物理地址空间:逻辑地址对应的所有物理地址的集合
由虚拟地址到物理地址的运行时映射是由内存管理单元(Memory-Management Unit, MMU)的硬件设备来完成。
一个简单的 MMU 方案:用户进程所产生的地址在送交内存之前,都将加上重定位寄存器的值

使用重定位寄存器的动态重定位
动态加载(Dynamic Loading)
采用动态加载时,一个程序只有在调用时才会加载,可以获得更好的内存空间利用率
当大多数代码需要用来处理不频繁的异常情况时很有用
不需要操作系统提供特别支持
动态链接(Dynamic Linking)与共享库
动态链接库(dynamically linked library)为系统库,可链接到用户程序,以便运行
链接会延迟到运行时
在二进制映像内,每个库程序的引用都有一个存根(stub)——用来指出如何定位适当的内存驻留库程序,或在程序不在内存内时应如何加载库的一小段代码
存根会用地址程序来替换自己,并开始执行程序
共享库(shared library)
交换
进程可以暂时从内存中交换到备份存储(backing store)上,当需要再次执行时再调回
需要动态重定位dynamic relocate
备份存储:是快速硬盘,而可以容纳所有用户的所有内存映像,并为这些内存映像提供直接访问,如Linux 交换区、windows 的交换文件 pagefile.sys
Roll out roll in:如果有一个更高优先级的进程需要服务,内存交换出低优先级的进程以便装入和执行高优先级进程,高执行完后低再交换回内存继续执行。
交换时间的主要部分是转移时间 transfer time。总转移时间与所交换的内存大小成正比。系统维护一个就绪的可立即运行的进程队列,并在磁盘上有内存映像。
连续内存分配(Contiguous Memory Allocation)
内存通常分为两个区域:一个用于驻留操作系统,通常和中断向量一起放在低内存;另一个用于用户进程,通常放在高内存
每个进程位于一个连续的内存区域,与包含下一个进程的内存相连
内存保护
重定位寄存器含有最小的物理地址值
界限寄存器含有逻辑地址的范围

内存分配
多分区方法(multiple-partition method)
孔(hole):一块可用的内存
可用的内存块为分散在内存里大小不同的孔的集合
对于可变分区(variable-partition)方案,操作系统有一个表,用于记录哪些内存可用和哪些内存已用
当新进程需要内存时,系统为该进程查找足够大的孔
动态存储分配问题(dynamic storage-allocation problem)
- 根据一组空闲的孔来分配大小为 的请求,常用方法包括:
- First-fit:分配首个足够大的孔
- Best-fit:分配最小的足够大的孔,必须查找整个列表,除非列表按大小排序;产生最小剩余孔
- Worst-fit:分配最大的孔,必须查找整个列表,除非列表按大小排序;产生最大剩余孔
First-fit 和 Best-fit 在执行时间和利用空间方面都好于 Worst-fit
碎片(Fragmentation)
外部碎片(external fragmentation):单独一块内存不能满足请求,总的可用内存之和可以满足请求但不连续
内部碎片(internal fragmentation):进程所分配的内存比所需的内存大的部分
解决外部碎片问题的方法之一是紧缩(compaction),移动内存内容,以便所有空闲空间合并成一整块
只有重定位是动态的,并且在运行时进行的,才可以采用紧缩
外部碎片问题的另一个解决方案是允许进程的逻辑地址空间是不连续的,可用分段或分页的技术来实现
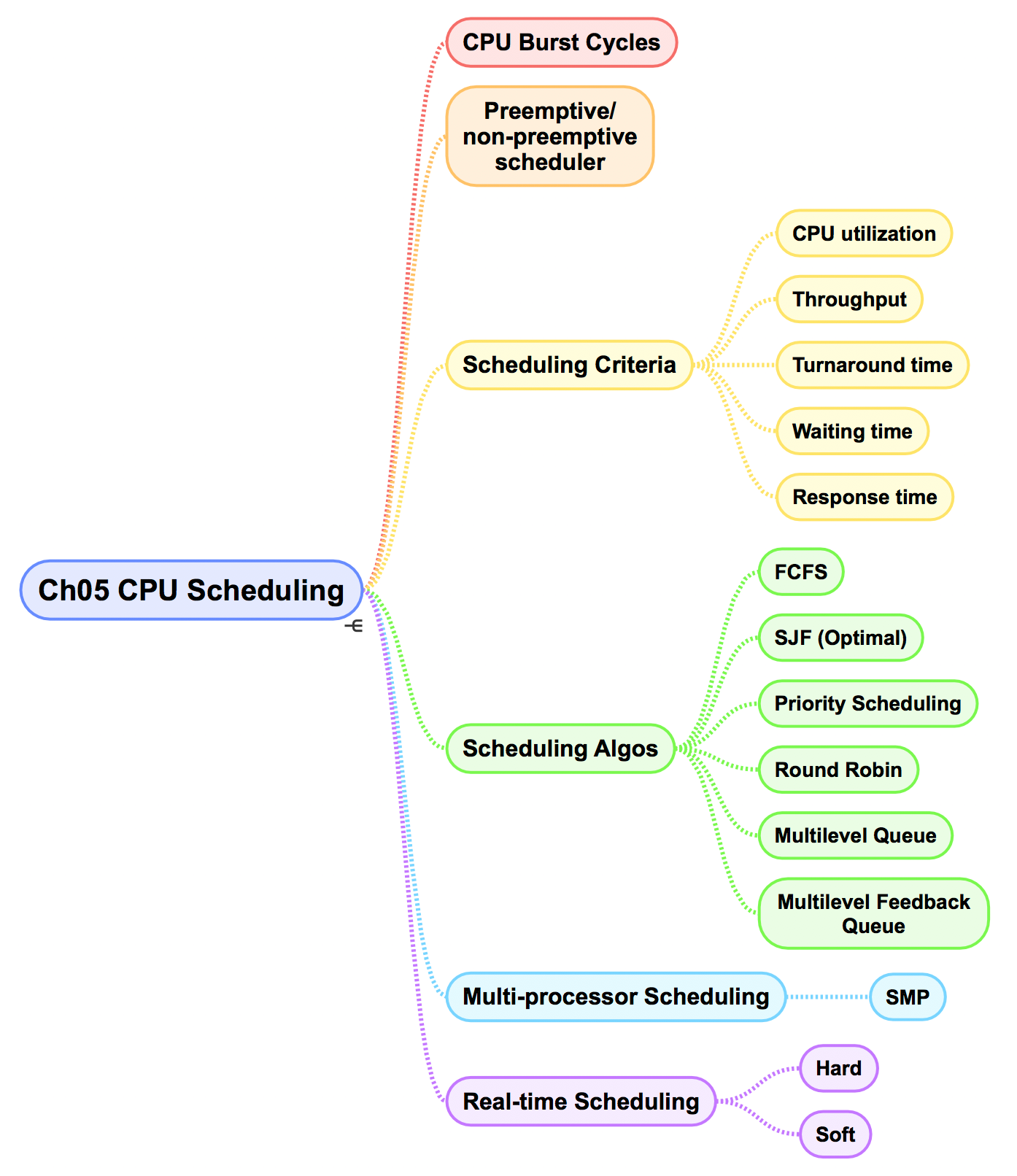
分页(Paging)
基本方法
将物理内存分为固定大小的块,称为帧或页帧(frame),通常为 2 的次方
将逻辑地址也分为与帧同样大小的块,称为页(page)
由 CPU 生成的每个地址分为两部分,页码(page number) 和页偏移(page offset)

逻辑地址空间为 ,页大小为 字节
页表(page table)包含每页所在物理内存的基地址,以页码作为索引

分页的硬件支持

空闲帧
硬件支持
页表基地址寄存器(Page-Table Base Register, PTBR)指向页表
页表长度寄存器(Page-Table Length Register, PTLR)指示页表的大小
采用这种方法访问一个字节需要两次内存访问,一次用于页表条目,一次用于字节,这样内存访问速度会减半。
解决方案是采用专用的、小的、查找快速的高速硬件缓冲,称为转换表缓冲区(Translation Look-aside Buffer, TLB),减少对内存的访问。
有的 TLB 在每个 TLB 条目中还保存地址空间标识符(Address-Space Identifier, ASID),唯一标识每个进程并为进程提供地址空间的保护。
并行搜索

带 TLB 的分页硬件
:硬件查找的开销,非常小
命中率(hit ratio):在 TLB 中查找到所需页码的次数的百分比
有效内存访问时间(effective memory-access time)需要根据概率来加权求和:
保护
分页环境下的内存保护是通过与每个帧关联的保护位来实现的
有效-无效位(valid-invalid bit)与页表中的每一条目相关联
当该位为有效时,表示相关的页在进程的逻辑空间内,因此是合法(或有效)的页
当该位为无效时,表示相关的页不在进程的逻辑地址空间内

页表的有效位(v)和无效位(i)
共享页
进程间可以共享一份只读可重入代码(reentrant code)或纯代码(pure code)的拷贝
共享代码必须出现在所有进程的逻辑地址空间中的同一位置
每个进程都有自己的寄存器副本和数据存储,以便保存进程执行的数据

分页环境的代码共享
页表结构
分层分页(Hierarchical Paging)
一个系统具有 32 位逻辑地址空间和 4K 大小的页,一个逻辑地址被分为 20 位的页码和 12 位的页偏移
两层分页算法将页表再分页,20 位的页码可再分为 10 位的页码和 10 位的页偏移

是用来访问外部页表的索引, 是内部页表的页偏移

两级页表

两级分页架构的地址转换
哈希页表(Hashed Page Table)
常用于处理大于 32 位地址空间,采用虚拟页码作为哈希值
哈希页表的每一个条目都包括一个链表,该链表的元素哈希到同一位置(该链表用来解决处理碰撞)
每个元素由三个字段组成:虚拟页码、映射的帧码、指向链表内下个元素的指针
最佳情况是每个链表只有一个元素

哈希页表
虚拟地址的虚拟页码哈希到哈希表,用虚拟页码与链表内的第一个元素的第一个字段比较,如果匹配成功,那么相应的帧码就用来形成物理地址,否则与链表内的后续节点的第一个字段进行比较
聚簇页表(clustered page table)用于处理 64 位地址空间,类似于哈希页表,不过哈希表内的每个条目引用多个页,这样单个页表条目可以映射到多个物理帧
倒置页表(Inverted Page Table)
所有进程共享同一个倒置页表,整个系统中只存在这一个页表
对于每个真正的内存页或帧,倒置页表才有一个条目
系统的每个虚拟地址为一个三元组:<进程 id,页码,偏移>
每个倒置页表条目为二元组:<进程 id,页码>,进程 id 用来作为地址空间的标识符
每个页表条目包含保存在真正内存位置上的页的虚拟地址,以及拥有该页进程的信息

倒置页表
减少了存储每个页表所需的内存空间,但增加了由于引用页而查找页表所需的时间
交换(Swap)
进程可以暂时从内存交换到备份存储(backing store),当再次执行时再调回到内存中

基于页的交换可以降低交换的粒度,提高性能
分段(Segmentation)
基本方法
分段是支持用户视图的内存管理方案
逻辑地址空间由一组段构成
逻辑地址由有序对组成:<段号,偏移>
分段硬件
段表(segment table)映射用户定义的二维地址到一维物理地址
- 段表的每个条目包含两个部分:
- 段基地址(segment base):包含该段再内存中的开始物理地址
- 段界限(segment limit):指定该段的长度

分段硬件